Novoscan 官方文档
深入了解 Novoscan 的技术架构、多代理推理引擎、数据检索体系和产品功能。
什么是 Novoscan
创新查重 / 评估领域的垂直化 AI 代理应用
「省下的是资源,算出的是未来」
Novoscan 是基于多智能体(Multi-Agent)架构的创新性分析品牌。 它整合了三条垂直业务线,覆盖从学术查新、开发者生态评估到商业想法验证的完整创新评估闭环—— 帮助用户在投入大量资源之前,用 AI 快速「算出」创新方向的可行性。
三大业务线
极速分析
数秒完成百万级数据检索与多维度 AI 推理
全维透视
学术 + 产业 + 竞品 + 开源 四维交叉验证
精准评估
量化创新指标,多名 AI 专家共识裁决
工作原理
Novoscan 的核心分析流程分为 5 个阶段,每个阶段紧密衔接,最终输出高可信度的创新性评估报告。
双轨并行检索
同时向全球学术数据库(OpenAlex、arXiv、CrossRef、CORE)和产业信号源(Brave Search、Serper、SerpAPI、GitHub、微信公众号、Google Scholar)发起并行检索,在数秒内获取跨维度原始数据。
多 Agent 深度推理
将检索数据分发给 4 名 Layer1 专家 Agent(学术审查员、产业分析员、竞品侦探、创新评估师),各 Agent 独立进行结构化推理和多维评分。
交叉质证与仲裁
仲裁员 Agent 汇集所有专家意见,动态调整置信度权重,解决评分冲突,给出加权综合评分和共识裁决。
质量检查
质量守卫 Agent 对最终报告进行逻辑一致性检查,标记异常和潜在偏差,确保输出质量达到工业级标准。
报告生成与可视化
将分析结果结构化渲染为可交互报告,包含 NovoStarchart 六维雷达图、高相似论文对标、产业信号图谱等可视化组件。
Novoscan 深度解读
Novoscan(常规模式)是三大业务线中的核心引擎,面向科研人员和技术团队, 提供学术 + 产业双维度创新性评估。它部署了4 层 6 Agent 精密编排拓扑和十源双轨检索引擎, 是整个 Novoscan 品牌的旗舰分析模式。
十源双轨并行检索
分析启动后,系统同时向学术和产业两条轨道发起并行检索:
交叉验证与可信度计算
双轨检索完成后,系统自动执行学术-产业交叉验证:计算概念重叠度、 领域一致性评分,并识别红旗信号(如学术热度高但产业空白、或产业落地快但学术基础薄弱), 为后续 Agent 推理提供校准后的可信度基线。
4 层 6 Agent 编排拓扑
6 Agent 职责详解
深度分析学术检索数据,从技术成熟度、论文覆盖度、学术空白、引用密度、发展趋势 5 个维度评估技术的学术基础。识别高相似论文并进行语义对标。
分析产业信号数据(网页搜索结果、商业产品信号、GitHub 开源项目作为低权重参考),评估技术在工业界的落地状况、市场热度和商业化成熟度。
从产业和学术数据中识别潜在竞品,分析竞争格局、技术壁垒和差异化空间。
综合三份 L1 报告进行交叉质疑,从原创性、技术壁垒、市场时机、执行可行性 4 维度评估创新性,生成 NovoStarchart 六维雷达图。
整合四位专家意见,根据置信度动态调整权重,系统性解决评分冲突,给出最终的加权综合评分、共识度判定和行动建议。优先使用 DeepSeek R1 深度推理模型。
对最终报告进行逻辑一致性审查,检测评分矛盾、证据链断裂等质量问题,确保输出达到工业级可信标准。
独特分析输出
NovoStarchart
六维创新性雷达图:技术突破、商业模式、用户体验、组织能力、网络协同、社会贡献
高相似论文对标
语义匹配最相似的学术论文,逐篇标注相似点和差异点
产业信号图谱
网页热度、商业产品信号、市场成熟度可视化
Follow-Up 追问
首次分析后支持多轮智能追问,逐步精化分析结果
智能降级策略
学术审查员降级
根据检索到的论文数量和引用密度推断学术空白度。0 篇命中 = 80 分(高度空白),每增 1 篇 -2 分,下限 15 分。
产业分析员降级
以网页搜索结果为主轴推断产业落地度(0 条 = 75 分),GitHub 仅做低权重微调(每个项目 -3 分,上限 -10 分)。
创新评估师降级
当 L1 Agent 全部超时时,基于原始检索数据的统计特征(论文数 / 引用量 / 搜索结果数)生成保守评分。
仲裁员降级
直接基于可用的 Agent 评分进行置信度加权。降级 Agent 权重自动调低,确保最终评分偏保守。
Novoscan Flash 极速模式
Novoscan Flash 是 Novoscan 的极速分析通道。它保留了核心的双轨检索能力, 但精简了 Agent 编排层——仅用单 Agent 快速评估替代完整的 4 层 6 Agent 拓扑, 将分析时间从 60-120 秒压缩到 10-20 秒。
原理
Flash 编排器(flashOrchestrator.ts)触发与标准模式相同的十源双轨并行检索, 但检索完成后仅调用一名综合评估 Agent 进行全维度推理。这名 Agent 同时扮演学术审查员、竞品侦探和创新评估师三个角色, 在一次 AI 调用中输出结构化评估报告。
适用场景
高频初筛
快速筛选大量创意,锁定值得深入分析的方向
时间敏感
会议中即时评估、头脑风暴快速验证
使用说明
在首页输入框下方,切换模式为「极速」(默认为标准模式)
输入研究想法,点击检查创新性
10-20 秒内获得精简版报告,含综合评分和核心发现
如需深入分析,可在报告底部切换至标准模式重新分析
NovoDiscover 跨域创新探索
NovoDiscover 是 Novoscan 的跨领域灵感发现引擎。 它运行一名独立的跨域侦察兵 Agent(Cross-Domain Scout), 负责在用户当前研究领域之外的领域中,识别可迁移的技术、方法和范式。
原理
跨域侦察兵 Agent 接收标准模式的检索数据和 NovoDNA 基因图谱(如有), 结合历史跨域桥梁数据库,通过类比推理(Analogical Reasoning)找出其他领域中解决类似问题的方案。 每条跨域桥梁包含:源领域、目标领域、迁移路径、可行性评分和参考案例。
使用说明
在标准模式下提交分析请求(Flash 不含此功能)
分析完成后,报告中自动展示「NovoDiscover 跨域创新迁移洞察」区块
查看每条跨域桥梁的源领域、迁移路径和可行性评分
展开跨域知识图谱可视化,直观了解领域间的关联网络
NovoDebate 辩论引擎
NovoDebate 是 Novoscan 标准模式中的对抗性验证机制。 当 Layer 1 专家 Agent 之间的评分分歧超过阈值时,系统自动触发辩手 Agent(Debater), 让持不同观点的 Agent 进行多轮结构化辩论,最终由仲裁员基于辩论结果调整评分。
原理
检测分歧:当两个 Agent 评分差 > 阈值时,自动配对为辩论组
正方陈述:高分 Agent 的立场和论据
反方质疑:低分 Agent 的反驳和证据
多轮交锋:最多 3 轮交替辩论,每轮均需回应对方论点
仲裁员裁决:基于辩论质量调整最终评分(调整幅度与辩论轮数挂钩)
使用说明
NovoDebate 完全自动触发——用户无需任何额外操作。当分析完成后,如果存在辩论记录, 报告中「辩论时间线」区块会自动展示:
分歧热力图
可视化各维度的分歧严重程度
辩论回放
逐轮展示正反方论点和反驳
隐私检索模式
隐私检索类似 Google Gemini 的「隐私对话」功能。 开启后,本次分析的所有数据不会被持久化到任何数据库—— 不保存搜索历史、不更新用户偏好、不写入创新趋势、不触发 Agent 记忆进化。 分析结果仅存在于当前浏览器会话中,关闭页面后即彻底消失。
保护范围
隐私模式在 API 层从源头拦截了以下全部写入操作:
跳过数据库写入
search_history 表不保存本次查询和分析结果
跳过趋势记录
创新点不提取到 innovations 表,不影响平台趋势统计
跳过 Agent 记忆
NovoscanEVO 不保存本次分析经验到记忆库
跳过用户画像
不记录搜索事件、不更新用户偏好和行为标签
不受影响的功能
隐私模式仅屏蔽数据持久化,以下核心分析能力完全保留:
十源双轨检索引擎照常运行,检索质量不受影响
4 层 6 Agent 完整拓扑正常推理(含 NovoDebate 辩论)
NovoDiscover 跨域探索照常触发
NovoDNA 基因图谱照常生成(仅不持久化)
使用说明
在搜索框下方工具栏中,点击「隐私检索」按钮(🔒 图标)
按钮变为紫色高亮态,表示隐私模式已激活
正常输入想法并提交分析,所有功能照常使用
分析完成后结果仅存在于当前页面,刷新或关闭后不可恢复
Clawscan 深度解读
Clawscan 是 Novoscan 针对 OpenClaw 生态的垂直业务线,覆盖Skill 查重和落地构想评估两大场景。 它通过3 层 4 Agent 编排拓扑和三路并行数据采集,为广大 OpenClaw 玩家提供便捷的 Skill 查重功能,并深入评估其 OpenClaw 落地生产场景想法的可行性。
三路并行数据采集
分析启动前,系统从三个数据源并行采集原始信号:
智能预处理管线
PII 脱敏引擎
用户输入可能包含邮箱、手机号、身份证等敏感信息
正则表达式实时脱敏:邮箱→[EMAIL]、手机→[PHONE]、身份证→[ID]、URL→[URL:域名]
AI 结构化解析
用户自然语言描述需要转换为结构化数据才能被 Agent 高效消费
AI 提取 7 个结构化字段:核心能力点、搜索关键词、同义词/英文对照、平台类型、分类、问题描述、目标用户
smartPreFilter 零 AI 预筛
全量 Registry 可能有数千个 Skill,全部送入 AI 分析成本过高
基于关键词匹配 + 安装量权重的零 AI 预筛,将候选集压缩到 18 个
3 层 4 Agent 编排拓扑
分析预筛后的候选 Skill 列表,计算每个 Skill 与用户构想的语义相似度(0-100%)、匹配功能点、覆盖率。输出排序后的 Skill 匹配清单。
分析网络搜索和 GitHub 数据,识别 OpenClaw 落地实战案例,提取关键洞察(技术栈、部署规模、相关度评分)。输出结构化案例清单。
交叉验证 Registry 匹配结果和实战案例,识别创新亮点和差异化因素,分析生态空白区域。输出创新度评价和 Gap 分析。
综合三份报告,计算综合评分(0-100)和重复度等级(none/low/medium/high),输出 Grade(S/A/B/C/D/F)、一句话判定和分类行动建议(proceed/differentiate/pivot/abandon)。
独特分析输出
Skill 匹配清单
按语义相似度排序,展示匹配功能点和覆盖率,Top 10
功能覆盖矩阵
用户核心能力 vs 现有 Skill 覆盖情况的全景对照表
实战案例库
OpenClaw 落地案例,含技术栈、部署规模和关键洞察
Bizscan 深度解读
Bizscan(商业查重)是 Novoscan 面向创业者和产品经理的商业想法评估系统。 它部署了5 层 7 Agent 工业级编排拓扑,是 Novoscan 三大模式中最复杂、最深度的分析引擎。
四源产业信号采集
Bizscan 的数据采集覆盖四个维度的产业信号源:
5 层 7 Agent 编排拓扑
Bizscan 采用比常规查重更复杂的分层依赖编排。Layer 内部并行执行,Layer 之间串行,总串行等待仅 3 次, 在保证分析深度的同时最大化并行效率。
7 Agent 职责详解
模拟 McKinsey/BCG 市场研究分析师。5 步推理:行业识别 → TAM/SAM/SOM 推算 → 增长趋势 → 饱和度 → 需求验证。输出市场规模估算、增长趋势(explosive/growing/stable/declining)和饱和度(oversaturated~blue-ocean)。
模拟 YC/a16z 竞争情报分析师。5 步分析:竞品全景扫描 → 分层(直接/间接/潜在威胁)→ Top3-5 深度拆解 → 护城河分析 → 进入壁垒。输出 3-8 个竞品详细档案。
充当'魔鬼代言人',质疑每个创新点。将想法拆解为 P(问题)/S(方案)/M(模式)三层逐层查重,判定创新类型:A类(范式)→ B类(组合)→ C类(增量)→ D类(伪创新)。
模拟资深 CTO。5 维评估:技术栈成熟度 → 成本结构(开发/基础设施/获客)→ MVP 时间线 → 规模化难度 → 风险清单。对 MVP 速度和团队门槛量化评分。
Bizscan 独有层。作为元分析师(Meta-Analyst),不分析商业想法本身,而是分析其他分析师的报告。识别分歧(>20 分差异)、证据冲突,输出校准后的四维评分和一致性评分。
模拟顶级 VC 合伙人。基于校准评分计算 BII 指数(加权公式),AI 可在 ±5 范围微调。输出 Grade 评级、一句话判定、3-5 条可执行战略建议和风险警告。
纯逻辑层。6 项检查:降级标记 → 极端值检测 → BII 一致性 → 评分分散度 → 交叉验证一致性 → 必填字段完整性。输出一致性评分 0-100 和 pass/fail。
BII 商业创新指数
Bizscan 的最终评分使用独创的 BII(Business Innovation Index)指数体系。
BII = 语义新颖度 x 0.25 + 竞争态势 x 0.30 + 市场空白 x 0.25 + 可行性 x 0.20
| Grade | BII 区间 | 含义 |
|---|---|---|
| S | ≥ 90 | 🏆 极具投资价值,市场空白 + 高可行性 |
| A | 75-89 | 🥇 优秀,差异化明显,值得全力推进 |
| B | 55-74 | 👍 良好,有差异化空间,需精准定位 |
| C | 35-54 | ⚠️ 一般,竞争中等,需强化差异化 |
| D | < 35 | ❌ 风险高,竞品密集或可行性低 |
智能降级策略
市场侦察员降级
根据网页搜索结果数量推断市场蓝海度:0 条 = 70 分,每增 1 条 -2 分,下限 20 分。同时推断市场饱和度(>15条 = crowded)。
竞品拆解师降级
综合网页结果 + Product Hunt 产品数推断竞争密度:0 条 = 80 分,每增 1 条 -3 分,下限 15 分。
交叉验证引擎降级
直接取各 Agent 原始评分作为校准评分,一致性分标记为 50 分,并在证据冲突中标注异常。
战略仲裁官降级
基于校准评分直接计算 BII 加权值,确定 Grade。AI 可在 ±5 分范围内微调 BII,超出则强制回退基准值。
NovoDNA 创新基因图谱
NovoDNA 是 Novoscan 的创新基因提取引擎,采用折叠式设计。 它从每次分析中提取课题的 5 维创新基因向量(原创突破 / 技术深度 / 应用广度 / 时效趋势 / 跨域迁移), 并构建持续进化的创新基因图谱。
折叠式交互设计
折叠态
雷达图 + 唯一性评分 + 5 维向量数值,一屏快速线览核心指标
展开态
星座图、密度热力图、突变推荐、邻居卡片、空白地带等全量可视化
5 维基因向量
DNA Harvester 收割器
后端配套 DNA Harvester 收割器,通过 Vercel Cron 每周一自动执行, 从 OpenAlex 拓取各领域高引论文,提取 5 维 DNA 向量并入库。配合零 AI 调用的领域分类器(覆盖 12+ 学科)自动打标签, 持续丰富基因库与创新图谱的密度。
双向进化机制
NovoDNA 与 NovoDiscover 形成正反馈闭环: 每次分析产生的新基因会丰富基因库,而 NovoDiscover 在下次分析时会参考基因库中的交叉领域候选基因, 实现「搜索优化 DNA → DNA 反哺搜索」的双向进化。
使用说明
NovoDNA 自动运行于 Novoscan、Bizscan 和 Clawscan 三大业务线。 分析完成后,报告中会展示「NovoDNA 创新基因图谱」折叠卡片,点击展开可查看全量可视化。
NovoscanEVO 智能体记忆进化
NovoscanEVO 赋予 Novoscan 的 Agent 集群跨会话学习能力。 每次分析不仅服务当前用户,还会将分析经验沉淀到 Agent 记忆库中, 使得系统在后续分析同领域课题时越来越精准。
原理
NovoscanEVO 基于 RAG(Retrieval-Augmented Generation)范式:
经验提取:每次分析完成后,提取评分校准教训、领域特征和分析策略
记忆存储:结构化经验写入 Supabase,按领域和主题索引
记忆检索:下次分析时,根据输入主题从记忆库中检索最相关的过往经验
上下文注入:检索到的经验作为额外 Prompt 注入各 Agent,引导更精准的推理
使用说明
NovoscanEVO 完全自动运行。当报告中出现「NovoscanEVO 智能体记忆进化」面板时, 说明本次分析参考了历史经验。面板展示经验来源数量、匹配的主题和具体洞察。
NovoCredits 积分体系
NovoCredits 是 Novoscan 的积分消费系统。 用户通过注册、邀请、兑换码等方式获取 Credits,用于兑换各项分析服务。
积分获取
| 获取方式 | Credits |
|---|---|
| 🎁 新用户注册 | 100 Credits |
| 👥 邀请好友(双方) | 各 50 Credits |
| 🎫 兑换码兑换 | 按码面值 |
积分消费
| 功能 | 消耗 |
|---|---|
| ⚡ Novoscan Flash | 0 Credits(免费) |
| 🔬 Novoscan 标准模式 | 10 Credits / 次(含追问生成) |
| 🔄 追问精化分析 | 10 Credits / 次(等同常规分析) |
| 💼 Bizscan 商业评估 | 10 Credits / 次 |
| 🔍 Clawscan Skill 查重 | 10 Credits / 次 |
使用说明
登录后,头像下拉菜单显示当前 Credits 余额
进入「个人中心」→「NovoCredits 积分账户」查看详细流水
在积分账户下方输入兑换码即可充值
邀请好友:个人中心获取专属邀请链接,好友注册后双方自动获得奖励
NovoTracker 趋势监控
NovoTracker 是 Novoscan 的持续监控系统。 它允许用户为自己关注的研究方向设置自动化定期扫描任务(每日两次 Cron), 系统会按照设定频率自动重新分析,并在发现显著变化时推送通知。
原理
用户创建监控任务:选择想法、监控频率(每日/每周/每月)和通知渠道
Vercel Cron 每日 02:00 和 14:00 UTC 触发扫描,执行 Flash 分析获取最新评分
系统对比历史评分,检测显著变化(评分波动 > 阈值)
变化达到预警条件时,通过多通道推送通知
通知渠道
邮件 / Server酱 / Telegram
面向用户的多通道预警通知
Webhook 推送
Cron 执行后自动推送结果至飞书 / Slack / 企微 / 自定义 URL
健康检查端点
内置 /api/tracker/health 端点,实时报告 Cron 运行状态(healthy / degraded / critical), 检测过期和错过 48h+ 的监控任务,为运维提供可观测性。
使用说明
登录后进入 Tracker 页面(导航栏 → Tracker)
点击「添加监控」,输入想法描述和监控频率
在个人中心 → 通知设置中配置接收渠道(邮件/Server酱/Telegram)
Tracker 仪表盘实时展示所有监控任务的评分变化曲线
NovoMind 对话式创新人格评测
NovoMind 是 Novoscan 的对话式创新人格评测系统。 采用三代理架构(访谈代理 + BARS 评估代理 + IDEA 评估代理),通过 5-15 轮自然对话, 同时生成五维创新力量化评分和四维创新人格原型画像。
三代理架构
使用 DeepSeek R1 进行隐式推理。V4 灵活版:万人通用开场白、动态深度调节、五维度覆盖保障。中期自动检查缺失维度并引导话题补全。
基于行为锚定等级评价量表(BARS),从五个维度独立量化评分(1.0-5.0)。每个维度附带原话引用和推理依据。
基于四维双极模型(Input/Direction/Execution/Alliance),输出 0-100 分和 16 型创新人格原型代码(如 VDPS → 布道师)。
BARS 五维评估
IDEA 四维人格模型
| 族群 | 成员 | 核心特征 |
|---|---|---|
| 🔥 点火者 | 布道师 / 发明家 / 造梦师 / 哲学家 | 远见驱动,善于开创 |
| 🏛️ 掌舵者 | 指挥官 / 先锋 / 元帅 / 建筑师 | 战略导向,精准执行 |
| 🔍 发现者 | 炼金师 / 侦探 / 大使 / 猎手 | 洞察驱动,善于发现 |
| ⚙️ 守护者 | 操盘手 / 工匠 / 总管 / 督察 | 稳健务实,确保品质 |
行为信号收集 & 画像进化
用户在 Novoscan 的日常操作(搜索、追问、推荐点击)被自动收集并映射到 IDEA 四维度, 持续校准对话画像。每 20 个行为数据点自动解锁偏差洞察报告——展示"你说的 vs 你做的"差异分析。
使用说明
在个人中心找到 NovoMind 卡片,点击「开始评测」
与 AI 进行 5-15 轮自然对话,AI 会通过开放式提问引导你分享思考方式
对话结束后,系统并行调用 BARS + IDEA 双评估代理生成报告
查看 BARS 五维评分(含行为锚定证据)和 IDEA 创新人格原型卡片
持续使用 Novoscan 搜索 → 行为数据积累 → 画像精度提升 → 解锁偏差洞察
MCP 远程服务 (Model Context Protocol)
Novoscan 提供符合 MCP 协议的远程服务端点, 允许 Claude Desktop / Cursor / ChatGPT 等主流 LLM 客户端直接调用 Novoscan Flash 分析能力。 开发者可以在自己的 AI 工作流中无缝集成创新性评估。
原理与架构
MCP 服务基于 mcp-handler 适配器和 @modelcontextprotocol/sdk 构建, 通过 Streamable HTTP 传输协议暴露工具。服务端点位于 /api/mcp。
暴露工具
novoscan_analyze
创新性极速评估。输入想法描述 + 可选领域/语言,返回 0-100 评分和结构化报告
novoscan_status
服务状态检查。返回版本号、运行状态、时间戳
双通道鉴权
OAuth 2.0 流程:通过 /api/oauth/authorize → /api/oauth/token 获取 Bearer Token,适用于 ChatGPT 等支持 OAuth 的客户端
API Key 直传:通过 Supabase mcp_api_keys 表管理订阅密钥(含计划等级、每日限额、有效期),环境变量 MCP_API_KEYS 兆底
required: false 模式运行,兼容无 OAuth 的客户端(如 Cursor)。最长支持 120 秒超时。快速接入
在 Claude Desktop 或 Cursor 的 MCP 配置文件中添加:
{
"mcpServers": {
"novoscan": {
"url": "https://your-domain.com/api/mcp"
}
}
}使用说明
获取 API Key:由管理员在 Supabase mcp_api_keys 表中创建,或通过环境变量 MCP_API_KEYS 配置
配置客户端:将上述 JSON 添加到 Claude Desktop / Cursor 的 MCP 配置文件
调用工具:在对话中请求 AI 客户端评估某个创新想法,客户端会自动调用 novoscan_analyze 工具
查看结果:AI 客户端收到 JSON 格式的评分 + 报告,并以自然语言呈现给用户
CaseVault 落地案例图谱
CaseVault 是 Novoscan 的 AI Agent 落地案例可视化图谱。 它收录并整理了全球 OpenClaw / AI Agent 在各行业的部署案例,以直观的分类导航帮助用户了解前沿实践。
核心功能
行业落地图谱
按行业/技术/规模维度分类的 AI Agent 真实部署案例
趋势可视化
多维度数据可视化,一目了然掌握行业落地趋势
差异化分析
对比同类 Skill 的落地方式,发现差异化空间
灵感发现
从成功案例中获取创新灵感和最佳实践
探索全球 AI Agent 落地变例
查看行业分布、技术趋势和最佳实践图谱
多代理架构
Novoscan 的核心竞争力在于其工业级多智能体(Multi-Agent)推理架构。 不同于传统的单一 AI 模型分析,Novoscan 部署了 6 名各司其职的 AI 专家代理,采用分层并行 + 串行的执行拓扑。
深度分析学术检索数据,从技术成熟度、论文覆盖度、学术空白、引用密度、发展趋势 5 个维度评估技术的学术基础。识别高相似论文并进行语义对标。
分析产业信号数据(网页搜索结果、商业产品信号、GitHub 开源项目作为低权重参考),评估技术在工业界的落地状况、市场热度和商业化成熟度。
从产业和学术数据中识别潜在竞品,分析竞争格局、技术壁垒和差异化空间。
综合三份 Layer1 报告进行交叉质疑,从原创性、技术壁垒、市场时机、执行可行性 4 个维度评估创新性,并生成 NovoStarchart 六维雷达图。
整合四位专家意见,根据置信度动态调整权重,系统性解决评分冲突,给出最终的加权综合评分、共识度判定和行动建议。优先使用 DeepSeek R1 深度推理模型。
对最终报告进行逻辑一致性审查,检测评分矛盾、证据链断裂等质量问题,确保输出达到工业级可信标准。
数据源与检索引擎
Novoscan 采用双轨并行检索引擎,同时从学术和产业两个维度获取原始数据,确保分析的全面性和权威性。
学术检索轨道
四源聚合检索,覆盖全球主流学术数据库:
产业信号轨道
六源产业信号捕获,追踪技术在工业界的真实落地状况:
NovoStarchart 评分体系
NovoStarchart 是 Novoscan 独创的六维创新性评估雷达图,由创新评估师 Agent 在综合分析后生成, 为用户提供直观的创新性全景视图。
六维评估维度
NovoStarchart 基于德布林十型创新模型(Doblin Ten Types)、IDEO DVF 框架、Henderson-Clark 分类法和ESG 标准, 从以下六个维度对创新点进行独立评估(每个维度 0-100 分):
产品功能独特性、技术含量、相对于现有方案的性能提升幅度
- ▸组件知识和架构知识的创新程度(渐进式→架构→激进式)
- ▸是否带来性能量级跨越而非渐进提升
获利逻辑是否打破行业常规(如买断→SaaS、免费增值等)
- ▸商业活力:LTV/CAC 比率、收入多元化程度、战略契合度
- ▸能否形成自我强化的飞轮效应
是否解决真实的、尚未被满足的用户痛点
- ▸品牌情感连接、交互深度(NPS / CSAT / CES 指标潜力)
- ▸是否开创全新的用户体验范式
从概念到落地的执行路径是否清晰
- ▸技术成熟度(TRL)、创新准备水平(IRL)
- ▸是否可快速迭代且流程高效
是否能构建平台/生态效应、产品系统协同
- ▸与外部合作伙伴的互补性、生态锁入效应
- ▸网络效应随用户增长的增强程度
对资源消耗、碳排放的降低程度
- ▸社会投资回报率(SROI)、包容性与公平性
- ▸是否引领行业 ESG 标准
综合创新评级
六维均分映射至 S / A / B / C / D 五个等级,直观传达创新段位:
| 等级 | 均分区间 | 含义 |
|---|---|---|
| S | ≥ 80 | 颠覆创新 — 高壁垒、时机完美 |
| A | 65-79 | 高度创新 — 有明确壁垒,值得推进 |
| B | 50-64 | 具备创新 — 有一定可行性但壁垒不高 |
| C | 35-49 | 创新一般 — 渐进式改进,竞争优势不明显 |
| D | < 35 | 创新不足 — 创新性极低或完全不可行 |
▸ 德布林十型创新(Doblin Ten Types of Innovation)— 维度 1-4 的设计框架
▸ IDEO DVF(Desirability / Viability / Feasibility)— 三角交叉校验
▸ Henderson-Clark 分类法 — 组件知识 vs 架构知识的创新程度分级
▸ ESG 标准(Environmental / Social / Governance)— 维度 6 的评估锚点
示例雷达图
以下是一份真实分析报告中 NovoStarchart 雷达图的效果示例:
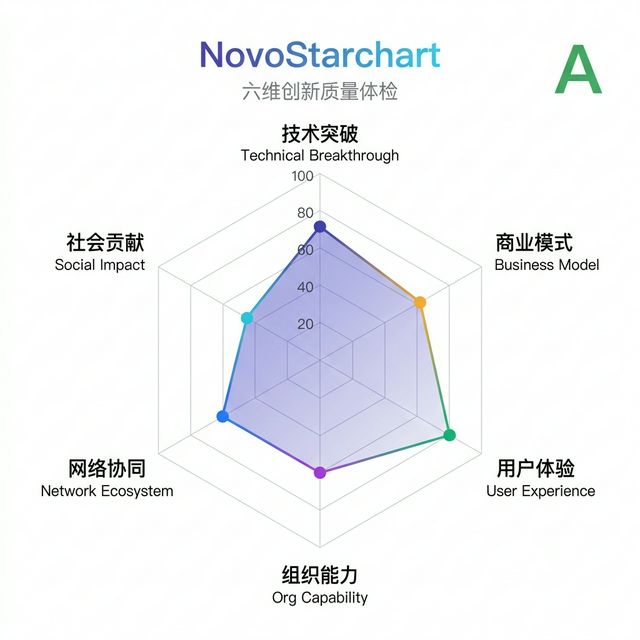
NovoStarchart 综合评级为 S/A/B/C/D 五级,右上角显示评级徽章。hover 每个数据点可查看维度评分理由。
六维交叉解读
NovoStarchart 六维之间并非孤立,特定组合能揭示创新质量的深层信号:
技术超前但执行路径模糊——典型的「实验室创新」,建议引入产业合作或分阶段验证
获利逻辑清晰且具备生态效应——容易形成自增强的竞争壁垒,是投资人最看好的组合
用户需求强烈但缺乏社会影响力——市场启动快但长期可能面临监管或 ESG 质疑
技术领先但尚未找到商业化路径——需要尽快验证付费意愿和定价策略
六维得分均衡说明创新成熟度高,没有明显短板——适合立即进入市场验证阶段
综合评分机制
最终的综合创新评分由仲裁员 Agent 通过加权算法生成。权重根据各专家 Agent 的置信度动态调整:
- 高置信度(high):权重系数 × 1.2
- 中置信度(medium):权重系数 × 1.0
- 低置信度(low):权重系数 × 0.7
同时,仲裁员会评估专家之间的共识度(strong / moderate / weak),并记录少数派异议, 确保评估结果的透明度和可追溯性。
智能追问系统
Novoscan 的Follow-Up 智能追问系统允许用户在首次分析后进行多轮深度追问,逐步精化分析结果, 挖掘更深层次的洞察。
工作流程
首次分析完成后,系统自动生成 3-5 个基于分析结果的追问问题
用户可选择感兴趣的追问问题,也可输入自定义问题
系统重新触发多 Agent 分析流程,注入追问上下文进行精化推理
报告实时更新,评分和分析结论根据新信息动态调整
支持多轮追问(Round 2, 3, ...),每轮都会生成新的追问建议
工程亮点深度解读
Novoscan 不是一个简单的 API 调用包装器,而是一个经过深度工程优化的工业级系统。以下是我们引以为豪的核心技术实现。
智能降级 Fallback 引擎
传统方案中,Agent 超时直接返回固定分数(如 50 分),导致信息丢失严重
基于原始检索数据的统计特征进行分布推断生成有信息量的降级评估
AbortController 资源回收
Agent 超时后底层 AI API 调用仍在运行,浪费昂贵的 Token 和服务器资源
超时时通过 AbortController 立即取消底层 fetch 请求,实现零浪费超时控制
置信度驱动的动态权重仲裁
不同 Agent 的分析质量参差不齐,简单平均会被低质量评分拖后腿
仲裁员根据每个 Agent 自报的置信度(high/medium/low)动态调整其在最终评分中的权重
十源双轨交叉验证引擎
单一来源的数据会存在偏见和盲区,仅靠学术数据无法反映工业界现状
学术四源 + 产业六源并行检索,自动计算一致性评分、概念重叠度,并识别红旗信号
质量守卫纯逻辑审查
AI 生成的报告可能存在逻辑矛盾(如评分很高但结论很负面),影响用户信任
质量守卫 Agent 对最终报告进行纯逻辑一致性审查(不调用 AI API),毫秒级完成
数据高利用率架构
Novoscan 对从十个数据源检索到的每一比特数据都进行了极致利用。 数据不仅被 Agent 消费用于推理,还会在报告的不同层级中以多种形式呈现给用户。
四层数据消费链
每一条检索数据至少被消费 4 次:
Agent 推理输入
原始检索数据(论文标题/摘要/引用/GitHub Star/网页摘要)作为 Agent Prompt 的一部分,驱动 AI 深度推理。每个 Agent 独立消费和解读同一份数据。
Agent 输出重组
Agent 输出的 keyFindings、redFlags、dimensionScores、confidenceReasoning 从 4 个 Agent 聚合到统一面板,交叉展示优势 vs 风险对照。
交叉验证引擎
双轨检索结果在验证引擎中自动计算一致性评分、概念重叠度、学术/产业支撑度,生成独立的可信度报告。
原始数据透传
全部十源原始数据(论文列表、GitHub 仓库、网页讨论、微信公众号文章)完整透传到前端,用户可在报告底部按需展开查看每一条原始数据。
数据字段级利用清单
以学术侧数据为例,每个字段都被充分利用:
| 数据字段 | 消费位置 |
|---|---|
| 论文数量 totalPapers | 学术审查员评分 + 智能 Fallback 推断 + 检索原始数据面板 + 交叉验证 |
| 引用数 totalCitations | 引用密度维度评分 + Fallback 修正 + 统计卡片展示 |
| 平均引用 avgCitation | 学术成熟度推断 + Fallback 分数修正(>100 则 -10分) |
| 开放获取数 openAccessCount | 检索报告展示 + 数据可得性评估 |
| 分源计数 bySource | 四源分布标签(OA/AR/CR/CO)+ 原始数据面板 |
| 热门概念 topConcepts | 研究方向标签云 + Agent Prompt 注入 |
| 论文标题/摘要 | 语义相似度计算 + SimilarityBar 对标展示 + Agent 推理依据 |
| GitHub Stars | 竞品密度评分 + 开源生态排行 + 原始数据展示 |
| 市场情绪 sentiment | 产业热度标签(🔥热门/🌡️温和/❄️冷静) |
三层递进报告架构
Novoscan 的分析报告采用独创的「结论→证据→原始数据」三层递进架构, 让用户以最高效的方式消化信息:一屏看完核心结论,按需深入每一层证据。
结论仪表盘 Hero
一屏看完核心结论
证据摘要层
可折叠手风琴,按需展开
原始数据层
折叠区,需点击展开
创新趋势系统
Novoscan 基于平台上所有用户的分析活动数据,每 2 天计算一次创新趋势快照, 通过可视化图表展示全球创新热度变化。
趋势计算周期
每 2 天触发一次趋势快照计算(Cron Job 或 API 调用)
聚合该周期内所有分析记录:总搜索量、活跃创新数、新创新数、平均创新性评分
按学科领域统计分布:计算每个 Domain 的搜索占比和趋势变化
生成 TrendSnapshot 写入数据库,供前端图表消费
可视化组件
首页的创新趋势区域展示以下图表:
统计卡片
总创新数 / 近 7 日搜索量 / 平均新颖度 / 活跃领域数,带动画计数器
趋势面积图
近 10 个周期的搜索量和新创新数变化趋势(Recharts Area)
领域分布柱状图
各学科领域的搜索量分布,带学科图标和配色
评分系统数学基础
Novoscan 的所有评分机制均可追溯到现实世界的数学学科和工业标准。 下文透明披露每个评分组件的理论基础,供审计和学术引用。
① 加权和模型(WSM)
Weighted Sum Model(加权和模型)是运筹学中最经典的多准则决策方法。 给定 n 个维度评分 s₁…sₙ 和对应权重 w₁…wₙ(∑wᵢ = 1),综合评分为:
▸ BII 公式:w = (0.25, 0.30, 0.25, 0.20),竞争态势权重最高因为创业领域竞争格局对结果影响最大
▸ NovoStarchart:不同 Agent 的置信度作为动态权重,属于 WSM 的自适应变体
▸ 文献:Fishburn, P.C. (1967) "Additive Utilities with Incomplete Product Set"
② 层次分析法(AHP)
Analytic Hierarchy Process 由 Thomas L. Saaty 于 1970 年代提出,是多准则决策分析(MCDA)的金标准方法。 NovoStarchart 的 6 维度评分体系参照了 AHP 的“目标层—准则层—方案层”分解思想:
综合创新评分
6 个维度
4 Agent 报告
▸ 文献:Saaty, T.L. (1980) "The Analytic Hierarchy Process", McGraw-Hill
▸ 其一致性比率(CR)检查思想对应了我们的质量护卫层
③ 贝叶斯后验加权
贝叶斯定理提供了在已知证据下更新置信度的数学框架。 Novoscan 的置信度加权机制直接复用了这一原理:
▸ 权重仲裁:high 置信度 Agent 的权重等价于“似然函数 P(E|H) 较大”,其评分在原始分基础上被放大
▸ 降级推断:Agent 超时时,利用已有数据构建先验分布 P(H),等价于贝叶斯先验估计
▸ 文献:Gelman, A. et al. (2013) "Bayesian Data Analysis", 3rd ed., CRC Press
④ 多评分者一致性(Fleiss' κ)
Fleiss' Kappa(κ)由 Joseph Fleiss 于 1971 年提出,是衡量多个评分者间一致性的统计量。 Bizscan 的交叉验证引擎的“一致性评分”直接映射了这一概念:
▸ 文献:Fleiss, J.L. (1971) "Measuring nominal scale agreement among many raters", Psychological Bulletin
⑤ Delphi 方法
Delphi 方法由兰德公司于 1950 年代提出,是结构化专家判断的金标准方法。 Novoscan 的多 Agent 架构完美复现了 Delphi 的核心流程:
▸ 文献:Linstone, H.A. & Turoff, M. (1975) "The Delphi Method: Techniques and Applications"
⑥ TF-IDF / BM25 变体
smartPreFilter 的关键词匹配 + 安装量加权机制是经典信息检索模型的简化变体:
▸ 名称匹配权重 5 → 等价于 TF-IDF 中 title field 的 boost factor
▸ log₁₀(installs) → 等价于 BM25 的文档权威度加成
▸ 文献:Robertson, S.E. & Zaragoza, H. (2009) "The Probabilistic Relevance Framework: BM25 and Beyond"
⑦ Mahalanobis 距离 / 异常检测
质量护卫层的“评分极端值检查”和“分散度检查”基于统计学中的异常检测原理:
▸ 文献:Tukey, J.W. (1977) "Exploratory Data Analysis", Addison-Wesley
⑧ 最大似然估计(MLE)
当 Agent 超时时,降级引擎基于已有数据的统计特征推断评分,这是最大似然估计的实战应用:
▸ 文献:Myung, I.J. (2003) "Tutorial on Maximum Likelihood Estimation", J. of Mathematical Psychology
隐私与安全
Novoscan 高度重视用户数据的隐私保护。系统提供多层隐私保障机制。
隐私模式
开启隐私模式后,分析记录不会被保存到本地 IndexedDB 或云端数据库。每次分析都是独立的一次性会话。
数据加密传输
所有数据传输均通过 HTTPS 加密通道,确保分析内容在传输过程中不被窃取。
最小化数据收集
系统仅收集分析所需的必要数据。用户偏好学习功能仅在登录状态下启用,且用户可随时关闭。
认证体系
基于 Supabase Auth 的安全认证体系,支持 Google OAuth 等主流登录方式。未登录用户有一次免费使用机会。
常见问题
© 2026 Novoscan · Powered by Multi-Agent Reasoning Engine
返回首页开始分析